


O Google não quer, de fato, promover uma Internet saudável, organizada e ética. Ele deseja continuar um império. E fará tudo quanto possível para atingir seus objetivos.
- O tamanho da empresa e o tamanho da fome
- A missão do Google
- O Google encorajou portais a “criar milhões de negócios sustentáveis focados em conteúdo na web”
- O Google prometeu dar aos editores pequenos e independentes uma oportunidade justa na web aberta
- O Google prometeu recompensar editores que investem recursos em conteúdo criado “por pessoas, para pessoas”
- Pessoas acreditaram nas promessas do Google
- A dependência ao Google
- GPTização do Google
- Para o Google ganhar, alguém precisava perder
- A discussão de uma pessoa só
- Google e Reddit
- O Google começa a demolir a web aberta para “reimaginar a pesquisa” do “zero” para um futuro centrado em IA
- O Google apagou silenciosamente “escrito por pessoas” de suas orientações para websites
- A atualização de conteúdo útil
- O Google inicialmente afirmou que estava apenas “shadowbanning” websites de “pouco valor”
- A promessa
- Promessas em vão
- O Google não permite que sites independentes pequenos apelem suas “shadowbans” (mas grandes empresas de mídia podem)
- Sites parasitas
- Denúncias públicas
- Sem alternativa
- O Google lançou os destaques de IA – duas semanas depois de purgar editores independentes
- O Google planeja usar a IA para monetizar não apenas as perguntas dos pesquisadores, mas também as respostas
- O Google também favorece suas próprias propriedades nos resultados de pesquisa
- De novo… o Reddit
- O Google planeja usar taxas de licenciamento de IA para controlar quais websites sobreviverão no futuro centrado em IA
- O Google é fortemente tendencioso a favor de poucos grandes conglomerados de mídia
- O Google planeja usar a IA para consolidar o fluxo de informações online
- O Google não está satisfeito com seu monopólio na busca – ele quer um monopólio nas respostas
- No Brasil, ainda há o turbilhão de Discover
Há alguns dias, recebi o material criado por Nate Hake, da Travel Lemming. Por um lado, vi um conteúdo extramente bem montado e aprofundado. Por outro, entendi que os maus resultados em seu projeto poderiam respingar em toda análise. “Você só está criticando o Google por ter resultados negativos, agora”, alguns podem pensar, por mais que o próprio Google tenha admitido problemas nas estruturas das atualizações que o penalizou.
Nesse sentido, nos últimos dias, me vi na condição de editar o trabalho, trazer novas fontes e colocá-lo em contexto brasileiro. Nesse sentido, toda atualização de conteúdo em português e específico do Brasil ou em primeira pessoa corresponde às visões de Não é Agência.
O tamanho da empresa e o tamanho da fome
Comecei esta edição me lembrando dos propósitos iniciais do Google e das dúvidas que os jovens acadêmicos tinham no início do Google.
Como Noam Shazeer, um executivo do Google, explicou recentemente, citando Larry Page: “Organizar informações é claramente uma oportunidade de trilhões de dólares, mas um trilhão de dólares não é mais legal. O que é legal é um quatrilhão de dólares.”
Sem dúvidas, os objetivos acadêmicos e profissionais de Larry Page e Sergey, que fizeram o Google nascer no mercado em 1998, estão longe dos objetivos comerciais de Pichai. E, provavelmente, dos próprios fundadores algum tempo depois.
Os caminhos atuais, inclusive, têm pouca relação com o passado. Hoje, o Google está mais preocupado em criar informações, a partir de sua Inteligência Generativa do que, de fato, organizar informações.
Talvez, no futuro, o slogan dá empresa possa ser “o Google faz a pesquisa para você”, sua IA e seus anúncios fornecem as respostas – e os usuários nunca precisam sair do Google. Em vez de “Dá um Google”, o caminho parece ser o “O Google dá a informação para você”. Ele cria.
No início, era diferente. Em uma entrevista, Page disse “a razão pela qual acho que realmente não vendemos a empresa foi que conversamos com todas essas empresas de busca, e elas simplesmente não estavam interessadas no que estávamos fazendo… Por que vamos trabalhar neste lugar que não acredita em busca? Isso não vai resultar em nada de bom”.
Para ele, a missão de organizar a informação era mais importante do que a venda, e ele não sentia que essa visão seria realizada dentro das outras empresas.
Essa missão existe até hoje? Parece-nos ser apenas uma caricatura do que já foi. Uma boa história a ser contada.
A missão do Google
Para contextualizar a censura do Google, preciso explicar brevemente o contrato social entre o Google e a web aberta – e como a IA ameaça mudá-lo.
De acordo com o Google, sua “missão é organizar as informações do mundo e torná-las universalmente acessíveis e úteis.” Nos primeiros dias da Internet, o Google ganhou popularidade prometendo ser um “mecanismo de busca puro” que apenas fornecia links para websites com “zero distrações”.

Em português, dizia “O Google (www.google.com) é um mecanismo de pesquisa puro – sem clima, sem feed de notícias, sem links para patrocinadores, sem anúncios, sem distrações, sem lixo no portal.
Nada além de um site de busca de carregamento rápido. Recompense-os com uma visita“.
Até hoje, a página oficial de filosofia corporativa do Google ainda afirma: “Podemos ser as únicas pessoas no mundo que podem dizer que nosso objetivo é fazer com que as pessoas saiam do nosso website o mais rápido possível.”

Isso pode até mesmo ser verdade, desde que seja para um anúncio. Podemos dizer que o Google deseja que você, rapidamente, veja um anúncio ulta-mega-blaster segmentado e vá para um página. Enquanto isso, por que você não faz uma nova pesquisa com nosso Modo IA e refine sua busca? Até lá, você verá um novo anúncio para ir rapidamente.
O Google criou um contrato social com a indústria editorial online: os editores fornecem conteúdo para o Google rastrear e, em troca, o Google envia cliques valiosos de volta aos editores.
Há 5 anos, o blog oficial do Google reconheceu a existência desse contrato social:
“O Google Search evoluiu desde seus primórdios, mas uma coisa que não mudou é a troca justa fundamental entre o Google e a web. O Google rastreia, indexa e linka para websites nos resultados de pesquisa, e cada resultado de pesquisa inclui uma breve prévia do que esperar no site. Os websites ganham tráfego gratuito de usuários interessados no que têm a oferecer, e cada visita de usuário é uma oportunidade de construir um relacionamento de longo prazo e monetizar por meio de publicidade ou assinaturas.”– Blog The Keyword do Google (26 de junho de 2020, ênfase adicionada)

Até hoje, o website do Google ainda afirma que a empresa acredita que a pesquisa deve “ajudar os criadores a ter sucesso online” e que:
“Para apoiar um ecossistema saudável de conteúdo novo e útil em todos os idiomas do mundo, ajudamos pessoas, editores e empresas de todos os tamanhos a ter sucesso e serem encontrados por outros. Fazemos isso enviando visitantes para websites pequenos e grandes através dos nossos resultados de pesquisa, ou por meio de conexões como listagem de endereços comerciais e números de telefone. Não cobramos para aparecer nas nossas listagens de pesquisa, e também fornecemos ferramentas e recursos gratuitos para ajudar os proprietários de sites a ter sucesso.”– Página do Google

Observe, aqui, a mudança de tom entre um passado recente e o presente. O Google deixou de lado enviar visitantes para sites pequenos e grandes” para focar em “não otimize para cliques”, como apresentamos.
Agora, o discurso majoritário já repetido por analistas e especialistas pelo mundo. “Bem, você não deveria focar nos cliques” ou “Tráfego é vaidade”. Esquecem que a Internet que conhecemos foi forjada para se ter cliques. E muitos negócios dependem disso.
Embora, rapidamente, o discurso mainstream tenha se modificado, a promessa continua estampada nos sites oficiais da empresa.
O Google encorajou portais a “criar milhões de negócios sustentáveis focados em conteúdo na web”
Vale ressaltar que o interesse em produzir conteúdo em troca de tráfego não foi uma ilusão coletiva. Foi um convite, inclusive do Google, para que as pessoas ajudassem, de certa forma, a própria empresa a organizar as informações.
O Google não apenas prometeu uma troca justa de conteúdo por cliques – a empresa ativamente encorajou os americanos a iniciar pequenos negócios online criando conteúdo.
Em 2018, o Google disse aos editores: “o mundo tem um apetite insaciável por ótimo conteúdo e editores como você permanecem o coração pulsante da web aberta. Compartilhar esta missão com você, ajudando a criar milhões de negócios sustentáveis focados em conteúdo na web, nos mantém em movimento.”

Meu primeiro projeto com monetização aconteceu em 2004, cerca de um ano depois do lançamento do Google AdSense. E faz muito sentido tal promessa estar em uma página que prometia monetização vinda de cliques.
Como mencionamos em outro local, hoje, o momento do Google é muito diferente do início do AdSense. Àquela altura, o faturamento com anúncios da empresa era praticamente meio a meio entre Pesquisa e Rede de Parceiros. Agora, o valor é menor que 10%.

Nesse sentido, o Google nunca dependeu tão pouco dos criadores para ser lucrativo. Inclusive, caso a própria parceria de monetização se encerrasse, não haveria um sério problema para a empresa do ponto de vista de rentabilidade.
O Google prometeu dar aos editores pequenos e independentes uma oportunidade justa na web aberta
É importante ressaltar que o Google prometeu que sua “troca justa fundamental” de conteúdo por cliques seria um mercado aberto não apenas para grandes publicações de notícias tradicionais, mas também para websites novos, pequenos e independentes.
Como vimos, naquele momento, era fundamental ao Google ter a visibilidade do sites para ver uma parcela significativa do seu faturamento.
Em 2014, quando o faturamento da Rede de Parceiros era superior a 25%, o representante do Google, Matt Cutts, disse aos editores em um vídeo: “Os pequenos caras podem absolutamente superar os grandes, desde que façam um trabalho realmente bom.”
Como os editores menores poderiam competir? Conteúdo de qualidade!
Cutts encorajou os sites: “não parem de tentar produzir conteúdo superior, porque, com o tempo, essa é uma das melhores maneiras de ranquear mais alto na web.”
Mas o que torna o conteúdo “superior” e digno de receber cliques do Google?
Bem, o Google também tinha algo a dizer sobre isso…
O Google prometeu recompensar editores que investem recursos em conteúdo criado “por pessoas, para pessoas”
O Google fornece aos websites extensa documentação sobre o tipo de conteúdo que o Google diz que busca recompensar com tráfego de pesquisa.
Ele afirma que “embora não haja garantia de que qualquer site específico será adicionado ao índice do Google, sites que seguem os Fundamentos da Pesquisa têm maior probabilidade de aparecer nos resultados de pesquisa do Google.”
No topo da lista de “principais práticas recomendadas” do Google para websites está a instrução de “criar conteúdo útil, confiável e focado nas pessoas.”
O Google tem uma página inteira com perguntas que os webmasters podem fazer para autoavaliar se estão criando o tipo de conteúdo que o Google busca recompensar. Alguns exemplos são:
- O conteúdo mostra informações, relatos, pesquisas ou análises originais?
- Ele inclui uma descrição significativa, completa ou abrangente do assunto?
- O material apresenta análises relevantes ou informações interessantes e originais?
- Quando o conteúdo é baseado em outras fontes, você evita simplesmente copiar ou reescrever e adiciona valor e originalidade ao material?
Em resumo, o Google afirma que recompensa editores que investem recursos e esforço em seu conteúdo – em oposição a spammers, que frequentemente usam sistemas de produção de conteúdo automatizados ou de baixo esforço.
Em agosto de 2022, o Google resumiu essa orientação em um agora infame post de blog anunciando que o Google estava “lançando uma série de melhorias na Pesquisa para facilitar a localização de conteúdo útil feito por, e para, pessoas.”

Vimos, naquele momento, como a Inteligência Generativa ainda engatinhando. Embora já existisse o GPT, ele não era um Chat. Estava nas mãos de poucos entusiastas que tentavam gerar algum conteúdo interessante com ferramentas terceiras, como era o caso do Jarvis (que depois se tornou Jasper).
Era um momento interessante para pedir conteúdo de pessoas para pessoas. Mas, mesmo naquela época, a Internet ainda estava cheia de conteúdo automatizado. Era comum, inclusive, ter traduções aos montes e sem crédito. Cópias baratas, muitas vezes, ocupavam boas posições, se publicadas por portais famosos.
Em 27 de empresa, o Google sempre teve dificuldades em combater o spam e o conteúdo de baixa qualidade. Por mais que vários sistemas tenham sido implementados, nunca estivemos próximos de combatê-los.
Pessoas acreditaram nas promessas do Google
Enquanto o Google prometia recompensas aos conteúdos que cumprissem com suas diretrizes, muitos editores viram que o buraco era muito mais embaixo.
Vale destacar que criar um conteúdo de qualidade, com ou sem IA, é muito trabalhoso. Alguns dos que estão aqui levaram vários dias de pesquisa e redação. Manter um sistema desse ao longo dos anos é uma tarefa custosa em todos os sentidos.
Das quedas que vimos em Discover, por exemplo, encontramos vários editores que contrataram especialistas para produzir os conteúdos. O próprio Nate Hake alega ter feito isso em seu blog.
Embora os portais realmente tivessem conteúdo autoritativo e especializado, regado à comunidade, os resultados não foram promissores em médio prazo para muitos deles.
Ter um conteúdo feito “por pessoas, para pessoas” tem um custo humano muito real. E esse custo só vale a pena se houver um ecossistema de web aberta que incentive adequadamente empreendedores talentosos a criar conteúdo de alta qualidade para a web.
O Google diz que apoia tal ecossistema, mas vejamos o que ele realmente faz…
A dependência ao Google
O Google prometeu aos editores uma “troca justa” de conteúdo por tráfego valioso. E, ao longo do tempo, a busca se tornou o principal motor de tráfego para a maioria dos websites de conteúdo.
Em um primeiro momento, tudo estava certo, uma vez que o Google continua nutrindo os editores com tráfego. Mas uma relação de dependência sempre está por um fio.
O tráfego de referência de pesquisa é uma fonte de receita ainda mais importante para websites informativos, como guias de viagem como o nosso. A pesquisa é onde os usuários buscam o tipo de conteúdo de guia longo que criamos.
E, como o Google tem um monopólio na busca, os editores online são fundamentalmente dependentes do Google. É a web de um monopolista, e nós estamos apenas publicando nela.
Em uma relação tão dependente, uma atualização de núcleo que prejudicasse 0,01% dos editores já teria um efeito danoso. Esse percentual eventual, que seria um grande número em termos absolutos, levaria diversos editores a uma rápida falência.
GPTização do Google
No final de 2022, apenas alguns meses após o apelo do Google por “mais conteúdo por pessoas, para pessoas na Pesquisa”, o ChatGPT tomou o mundo de assalto.
Os contornos começam a ficar mais dramáticos quando o GPT é anunciado. Claramente, o Google não tinha uma resposta pronta a um chat generativo naquele momento.
Ainda assim, cerca de três meses depois o Bard é anunciado. Em uma série de erros, as ações caem 8%.

Embora o Google já estivesse trabalhando em suas próprias ambições de IA há anos, o surgimento do ChatGPT supostamente fez com que o Google declarasse um “código vermelho” internamente – reestruturando dramaticamente a empresa, convocando seus ex-fundadores e reformulando tudo em torno da IA.
Em fevereiro de 2023, o então SVP do Google, Prabhakar Raghavan, anunciou que o Google estava “reinventando o que significa pesquisar.”
Frase que, inclusive, encontramos nas ofertas de contratação no LinkedIn:

No evento anual I/O do Google em maio de 2023, o CEO Sundar Pichai reiterou a extensão da mudança, dizendo: “Estamos reimaginando todos os nossos produtos principais, incluindo a pesquisa.”
Naquele momento, o primeiro gosto de Pesquisa com IA aparecia. A mídia anunciou:
“Os consumidores dos EUA terão acesso à Search Generative Experience (SGE) nas próximas semanas por meio de uma lista de espera, uma fase de teste durante a qual o Google monitorará a qualidade, a velocidade e o custo dos resultados da pesquisa, disse a vice-presidente Cathy Edwards em uma entrevista”.
A SGE era um modelo embrionário e improvisado do que conhecemos como AI Overviews.
Após o evento, o The Verge declarava que o futuro da empresa e, consequentemente, da Web estava próximo de ser modificado para sempre.
Naquele mesmo conteúdo, The Verge deixava claro que a ambição não era competir no mercado de Chatbots – que, a bem da verdade, também não é da OpenIA, mas o domínio completo de inteligência generativa. Para isso, a IA precisava dominar a Pesquisa, o ativo mais valioso da empresa.
Para o Google ganhar, alguém precisava perder
O Google tem até hoje, como vimos, o interesse em reimaginar a busca. Mas, como os próprios executivos sabem, isso tem um preço: rever o pacto efetuado no início da Internet.
Reimaginar a busca significa retrabalhar o contrato social que sustentou o ecossistema da web aberta por décadas, algo que o CEO do Google, Sundar Pichai, reconheceu na teleconferência de resultados do segundo trimestre de 2023 da Alphabet, em julho de 2023.
Nessa chamada, Pichai disse aos investidores que a IA apresentava “uma oportunidade de reimaginar muitos de nossos produtos, incluindo nosso produto mais importante, a Pesquisa” e que o Google estava “engajando com o ecossistema mais amplo e continuará a priorizar abordagens que enviem tráfego valioso e apoiem uma web saudável e aberta.”

“Acreditamos que todos se beneficiam de um ecossistema de conteúdo vibrante. Fundamental para isso é que os editores da web tenham escolha e controle sobre seu conteúdo, e oportunidades para derivar valor da participação no ecossistema da web. No entanto, reconhecemos que os controles existentes para editores da web foram desenvolvidos antes das novas IAs e casos de uso de pesquisa.” (ênfase adicionada)
Em suma, o Google reconhecia que qualquer abordagem justa para uma web “IA-first” exigiria a reescrita do contrato social subjacente da web.
A discussão de uma pessoa só
Embora o Google tenha convocado a comunidade para uma discussão pública, ela, de fato, nunca aconteceu.
O Google, falando explicitamente de controles no robots.txt – documento público que permite com que páginas possam ser rastreadas pelos bots, mostrava algum interesse em entender o que poderia ser feito para que os Publishers tivessem mais controle sobre como as IAs poderiam interagir com os conteúdos.
Como o protocolo oferece uma escolha muito “tudo ou nada” e não oferece aos editores o tipo de controle granular que precisamos para realmente controlar como nosso conteúdo é usado por sistemas de IA (e quais sistemas de IA).
E, infelizmente, isso continua até hoje.
Por que o controle granular é tão importante para os editores? Bem, porque os editores querem que o Google nos pague quando ele usa nosso conteúdo para seus recursos de IA. Mas não temos real poder de negociação se o Google já tem acesso ao nosso conteúdo para sua indexação de pesquisa.
Ou seja, você precisa decidir entre entregar seus conteúdos para serem processados por IA e aparecer na Pesquisa.
Como o Departamento de Justiça dos EUA explicou recentemente suas soluções propostas no caso antitruste de busca, os editores da web “têm pouco ou nenhum poder de negociação contra o monopólio do Google” porque o Google pode “alavancar seu poder de monopólio para alimentar recursos de inteligência artificial” com nosso conteúdo, que temos que fornecer se quisermos que nossos websites sejam visíveis na pesquisa online.
O Google agora se opõe à solução proposta pelo DOJ de dar aos editores mais controle granular sobre como as empresas de IA usam nosso conteúdo. Mas em seu post de blog de julho de 2023, o Google parecia concordar que o robots.txt não era suficiente:
“À medida que novas tecnologias emergem, elas apresentam oportunidades para a comunidade web evoluir padrões e protocolos que apoiam o desenvolvimento futuro da web. Um desses padrões web desenvolvidos pela comunidade, o robots.txt, foi criado há quase 30 anos e provou ser uma maneira simples e transparente para editores web controlarem como os mecanismos de busca rastreiam seu conteúdo. Acreditamos que é hora da comunidade web e de IA explorarem meios adicionais legíveis por máquina para a escolha e controle dos editores web para casos de uso emergentes de IA e pesquisa.” (ênfase adicionada)
Após essa postagem no blog, a prometida “discussão pública” do Google sobre o controle do editor da web nunca aconteceu de fato.
Atualmente, embora muitos defendam algum uso de LLM.txt, o Google se mostra completamente ausente da discussão que teria iniciado em 2023.
Embora, John Mueller tenha citado o Google-Extended, ele não permite por exemplo, que AI Overviews ou o modo IA não sejam treinados pelo modelo ou apresentem as informações. Para isso, apenas a proibição completa da pesquisa.

Google e Reddit
Editores não eram os únicos preocupados com o Google rastreando conteúdo para alimentar seus sistemas de IA.
Os proprietários da plataforma de mídia social Reddit foram muito persuasivos, argumentando que não era justo que as empresas de IA raspassem e usassem o conteúdo do Reddit gratuitamente. Eles até começaram a fazer barulho sobre o Reddit bloquear os rastreadores de pesquisa do Google.
Em um artigo do New York Times de abril de 2023, o CEO do Reddit, Steve Huffman, disse: “Rastrear o Reddit, gerar valor e não retornar nenhum desse valor aos nossos usuários é algo com que temos um problema… É um bom momento para apertarmos as coisas.”
Ao contrário dos editores independentes, no entanto, o Reddit realmente tinha influência sobre o Google.
O Reddit era o proprietário de um verdadeiro tesouro de conteúdo gerado por usuários históricos que o Google queria para seus grandes planos de IA. Se o Google pudesse fechar um acordo para o conteúdo do Reddit, talvez isso poupasse o Google da despesa de negociar acordos de licenciamento com os muitos editores e detentores de direitos díspares da web.
Ali, estavam conteúdos com autoridade e experiência, muito do que o Google sempre quis. Nesse momento, mais do que nunca, editores independentes passam a ser ainda mais desnecessários.
Veja, como uma notícia no Reddit gerou tantas reações, capazes de ajudar o Google a entender contextos e sentimentos rapidamente.
Não sabíamos na época, mas mesmo enquanto o Google enrolava os editores em 2023 com falsas promessas de uma discussão pública, nos bastidores o monopolista da busca estava negociando um contrato privado com o Reddit.
Enquanto isso, à medida que o verão de 2023 chegava ao fim, o Google trabalhava em atualizações de algoritmo que começariam a lançar as bases para sua versão “reimaginada” e IA-first de busca – e para um novo contrato social para a web que ele escreveria unilateralmente. Um novo contrato social que, como se veria, excluía editores independentes…
O Google começa a demolir a web aberta para “reimaginar a pesquisa” do “zero” para um futuro centrado em IA
No restante de 2023, muitos editores estavam muito apreensivos com a IA. Mas alguns ainda mantinham a esperança de que o Google pudesse guiar a web aberta de forma responsável através da transição para o futuro da IA.
Vários continuaram a investir exclusivamente em conteúdo “escrito por pessoas, para pessoas”, mesmo com o aumento da pressão na indústria para usar novas ferramentas de IA para criar conteúdo mais barato em escala. Importante, o Google ainda afirmava em sua documentação para webmasters que queria priorizar o conteúdo criado por humanos em seus algoritmos de classificação.
Isso significaria, em algum grau, que o Google entendia que os editores são o coração pulsante do ecossistema da web aberta – e que mesmo um futuro centrado em IA requer editores que criem material novo para que as IAs usem e aprendam. Na verdade, não.
A IA é um substituto pobre para os editores humanos. A IA é inerentemente derivada. A IA não consegue vivenciar o mundo. A IA não consegue visitar um lugar. A IA não consegue manusear um produto. A IA só pode pegar, resumir e regurgitar o que outros humanos reais criaram.
Em que pese que a IA pode e deve ajudar muito no processo de descoberta e, até mesmo, criação de conteúdos, não conseguimos ver que ela, sozinha, seja capaz de fazê-lo da maneira com que as pessoas desejam ler os materiais.
Pelo menos por enquanto, a IA não pega um metrô cheio na estação da Sé. Não vive com a periculosidade de determinados bairros. Não tem sensações genuínas nem experimenta, de fato, alguma coisa.
Por isso, as argumentações, sugestões e análises precisam ser tomadas a partir dos pensamentos de outras pessoas. Quando os editores menores são desincentivados a escrever, a análise passa mais por grandes blocos de comunicação e por conteúdo gerado por spam e opiniões pagas.
E, o mais importante, o Google havia passado os anos anteriores dando tanta importância ao desejo de elevar o conteúdo “feito por pessoas, para pessoas.” Depois de dar tanta importância à relevância do conteúdo humano, não seria hipócrita o Google de repente colocar o conteúdo de IA no centro da pesquisa?
O Google apagou silenciosamente “escrito por pessoas” de suas orientações para websites
O Google fez o que qualquer bom monopolista faz quando é pego quebrando as regras. Apenas mudou o livro de regras.
Em 14 de setembro de 2023, o Google atualizou discretamente sua documentação para remover “escrito por pessoas” de suas orientações para websites:
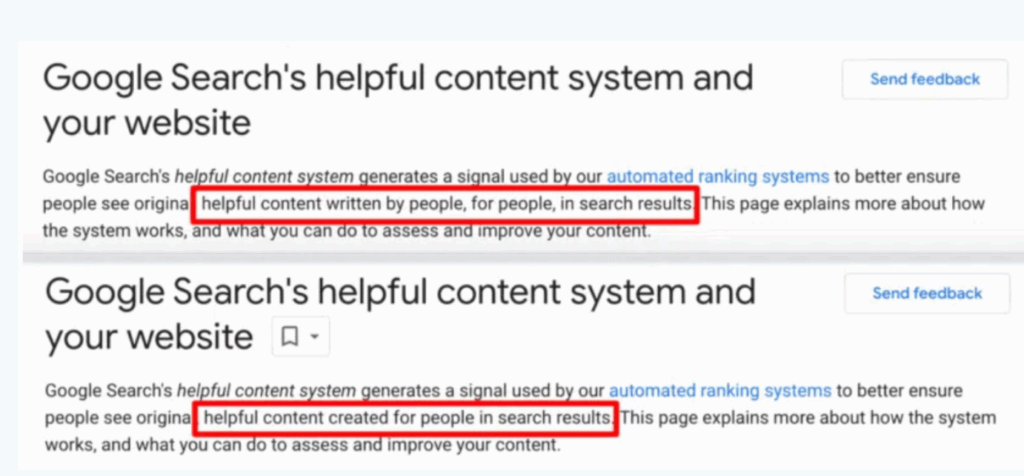
Uma captura de tela antes e depois mostrando a mudança do Google (Fonte: Search Engine Land)
Observe a mudança de postura. O que antes incentiva o conteúdo gerado por pessoas, agora menciona apenas conteúdo útil.
Veremos, mais tarde, que mesmo a parte útil tem sido esquecida pelo Google.
A atualização de conteúdo útil
Para reimaginar a pesquisa do zero, o Google teve que começar derrubando o que estava lá. Até o o meio de 2023, o Google sabia que queria inserir IA diretamente nos resultados de pesquisa.
Mas lançar a IA de uma só vez significaria uma queda massiva nos cliques para os editores – e uma potencial ameaça de litígio para o Google. Então, o Google iniciou seu projeto de demolição de IA arrasando as partes da web aberta menos capazes de revidar: os editores independentes.
Inclusive, esta é uma relação peculiar na história do Google. Por um lado, trabalhos independentes são encerrados a todos os momentos. Por outro, os grandes projetos sempre têm auxílio interno do Google na resolução dos problemas.
Nesse sentido, observa-se que os grandes portais até mesmo se recuperam mais rápido de determinadas punições, enquanto os pequenos, muitas vezes, podem dar adeus.
O Google implementou este projeto de demolição sob o pretexto de atualizações de algoritmo de classificação de pesquisa. O Google ajusta frequentemente seus algoritmos de classificação para mudar a forma como seus sistemas classificam o conteúdo da web. As atualizações de algoritmo anunciadas acontecem várias vezes por ano e são uma parte recorrente da vida dos editores na web aberta.
A orientação do Google para webmasters ainda afirma que “a maioria dos sites não precisa se preocupar com as atualizações centrais e pode nem perceber que uma aconteceu.” Isso significa, na teoria, que projetos que obedecem as diretrizes estariam imunes a quedas.
De forma geral, quando um site sofre oscilações, o efeito geralmente era apenas parcial (algo na ordem de uma queda de 10-25% no tráfego). E esses webmasters geralmente tinham oportunidades de melhorar seus sites e recuperar a classificação, o que frequentemente faziam.
Mas desta vez foi diferente. Em 14 de setembro de 2023 – no mesmo dia em que o Google removeu “escrito por pessoas” de suas orientações – um enorme algoritmo do Google foi anunciado. Vários sites, simplesmente, perderam todo tráfego relevante.
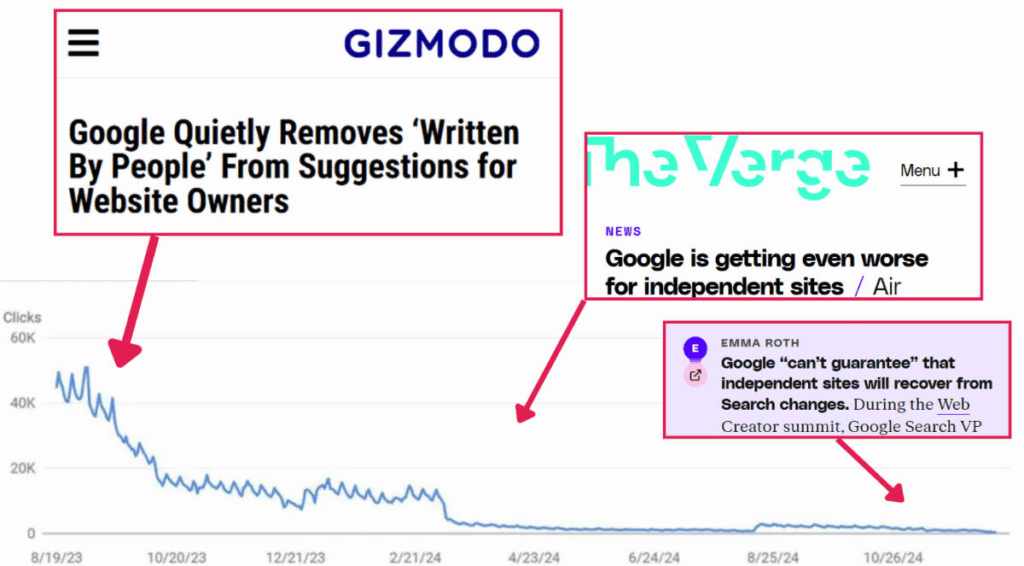
Um gráfico do relatório de tráfego de referência de pesquisa no site de Nate no Google Search Console, sobreposto com manchetes contemporâneas
O efeito no tráfego e nos negócios da Travel Lemming foi rápido e devastador. Aquela atualização de setembro que nos atingiu foi apelidada de “The Helpful Content Update” (Atualização de Conteúdo Útil). Foi uma atualização do sistema de conteúdo que o Google havia anunciado um ano antes. E foi apenas o começo do massacre…
Entre o outono de 2023 e a primavera de 2024, o Google desencadeou uma enxurrada de atualizações em uma escala que não era vista há quase uma década, tanto em termos de sua frequência quanto de seu efeito geral no ecossistema da web.
No momento em que essa onda de atualizações terminou em maio de 2024, alguns editores, como Nate, ficaram com cerca de 3% do tráfego anterior. Pode-se encontrar centenas de outros na mesma situação.
Talvez, você não tenha ouvido falar tanto sobre o assunto no Brasil. E foi exatamente por isso que criamos Não é Agência. No momento da queda do Discover, vimos centenas de pessoas sem ter a quem recorrer por aqui, precisando inclusive de ajuda internacional.
Nesse caso, o fato de você não ouvir falar não significa que não tiveram impactados, mas que eles não tiveram voz suficiente para serem ouvidos.
A enxurrada de atualizações do Google dizimou sites independentes em todas as áreas: sites de avaliação de produtos, sites de jogos, sites de entretenimento, sites de fitness e mais verticais sentiram a dor.
Em suma, entre a primavera de 2023 e outono de 2024 foi um banho de sangue absoluto para os websites independentes.
O setor de viagens em particular foi atingido com especial dureza. Uma análise da Digitaloft descobriu que 78% dos editores de viagens perderam tráfego orgânico durante essas atualizações – e 32% perderam mais de 90% de seu tráfego orgânico. Além disso, o punhado de editores de viagens que sobreviveram eram quase todos de propriedade de grandes corporações de mídia tradicionais.
O Google inicialmente afirmou que estava apenas “shadowbanning” websites de “pouco valor”
Quando a atualização “HCU” de setembro de 2023 foi lançada, o Google forneceu orientação por escrito aos proprietários de sites afetados. O Google excluiu essas declarações desde então, mas vocês podem vê-las abaixo.
O Google inicialmente afirmou que o algoritmo de “shadowban” que atingiu meu site “identifica automaticamente conteúdo que parece ter pouco valor, baixo valor agregado ou que não é particularmente útil para as pessoas.”
Era uma declaração que os sites em questão tinham pouco valor, de forma fria e vazia, por mais que as comunidades dos sites pudessem dizer o contrário.
Mas agora os algoritmos do Google estavam dizendo que todos aqueles sites tinham “pouco valor.”

Atualmente, a página anterior é redirecionada para esta:

Com um pequeno resumo, a página não destaca nenhuma informação útil para os que foram impactados.
A promessa
A orientação do Google também nos dizia que a recuperação era possível se apenas “removêssemos” nosso conteúdo “inútil” da página:
“Se você notou uma mudança no tráfego que suspeita estar relacionada a este sistema (como após uma atualização de classificação postada publicamente para o sistema), então você deve autoavaliar seu conteúdo e corrigir ou remover qualquer coisa que pareça inútil… Sites identificados por este sistema podem ter o sinal aplicado a eles por um período de meses. Nosso classificador funciona continuamente, permitindo monitorar sites recém-lançados e existentes. À medida que ele determinar que o conteúdo inútil não retornou a longo prazo, a classificação não será mais aplicada.”-Fonte: versão arquivada da orientação do Google, desde então excluída (ênfase adicionada)

Observe que o Google afirmou que estas eram atualizações baseadas em conteúdo e disse que tornar o conteúdo mais “útil” – ou excluir completamente o conteúdo mais fraco de um site – poderia levar à recuperação.
A documentação do Google afirmava ainda que o “classificador” que havia banido nossos sites funcionava “continuamente”, o que significava que seria constantemente recalculado em “tempo real”. Além disso, o Google disse que o classificador era “ponderado”. Se isso fosse verdade (o que não era), teria significado que pelo menos uma recuperação parcial era possível mesmo com apenas uma “melhora” parcial do conteúdo.
Em retrospectiva, o primeiro sinal das mentiras do Google foi que ele substituiu sites independentes por conteúdo que claramente violava as próprias diretrizes do Google (mas mais sobre isso mais tarde).
Apesar de sermos prejudicados pelo Google nos chamando de “pouco valor” e brutalmente nos banindo da web, muitos dos afetados levaram as declarações do Google a sério.
Nesse sentido, vimos equipes que investiram tempo e recursos para revirar o conteúdo em um esforço para “melhorá-lo” e atender ainda mais às diretrizes de conteúdo do Google.
Em alguns casos, vimos empresas removendo partes relevantes do índice com a expectativa de que só aquilo que era extremamente útil permanecesse. Em vão.
Os editores tiveram novos custos, mas, em vez de recuperar, viram novas quedas.
Promessas em vão
Mesmo depois de um ano, pouca coisa se viu.
Ninguém mais se recuperou.
De fato, como quase todos os sites independentes afetados, continuamos a perder classificações ainda mais – não importa o quanto o conteúdo tenha sido modificado. Algo parecia… errado.
Como se vê, os algoritmos que atingiram o nosso e outros sites não eram realmente baseados em conteúdo. Em vez disso, eventualmente ficou claro que eram realmente algoritmos baseados em “autoridade”. O que é uma maneira chique de dizer que o Google decidiu promover sites maiores em detrimento de pequenos – e isso na verdade não tinha nada a ver com conteúdo desde o início.
Isso explicava por que todos os investimentos em revisão ou exclusão de conteúdo não mudaram nada. Mas não explicava o que os editores independentes deveriam fazer em seguida.
O Google não permite que sites independentes pequenos apelem suas “shadowbans” (mas grandes empresas de mídia podem)
Em meados de 2024, nós e outros sites afetados estávamos em uma posição realmente terrível: não apenas foram “shadowbanned”, mas parecia que não havia nada que pudessem fazer a respeito.
O Google não oferece nenhuma forma de apelar de um “shadowban” algorítmico como o classificador que atingiu nosso site. É por isso que o Google geralmente evita implantar “shadowbans” algorítmicas contra grandes sites pertencentes a conglomerados de mídia, mesmo quando grandes sites quebram intencionalmente as políticas de spam do Google.
Em vez disso, como falamos, quando grandes sites quebram as regras do Google, o Google lhes aplica “penalidades manuais”. As grandes editoras então têm acesso a um processo estruturado de apelação e reconsideração. Representantes do Google até ajudam a guiar esses sites nas mudanças que precisam fazer, até que eventualmente recuperem suas classificações.
Além disso, recentemente, o Google assumiu que não havia nada de errado com os sites penalizados injustamente pela HCU. Por outro lado, disseram não existir um botão que possa reverter o processo.
Sites parasitas
Na maior parte dos casos, as punições manuais acontecem por problemas algoritmicos. O Google tem estrema dificuldade em avaliar a qualidade de um site por partes.
Ou seja, quando há como aconteceu com Forbes, ou mesmo com ISTOÉ, um claro e manifesto abuso de autoridade, os sistemas têm dificuldade em encontrar e separar aquilo que é bom daquilo que é ruim.
Por isso, com frequência, vemos bons conteúdos sendo desprezado, por teoricamente estar em um domínio fragilizado, enquanto toneladas de conteúdos ruins protagonizam grande tráfego pela qualidade geral do site.
Por exemplo, em março de 2024, o Google anunciou que supostamente reprimiria o “abuso de reputação de site” – uma prática em que grandes websites de marcas conseguem abusar da pontuação de autoridade de seu site para gerar conteúdo de baixo esforço em massa. Algumas dessas grandes publicações são até conhecidas por alugar URLs em suas páginas para spammers terceirizados, uma prática conhecida na comunidade de spam como “Parasite SEO.” Esta prática de spam só é possível devido à forma como o algoritmo do Google agora favorece fortemente os sinais de “autoridade” de um site (em oposição a realmente medir a utilidade do conteúdo).
Esses grandes sites estavam abusando das políticas de longa data do Google contra conteúdo de baixo esforço. E estavam fazendo isso intencionalmente. Mas, ainda assim, o Google fez algo sem precedentes: deu a esses grandes sites vários meses de aviso prévio para se organizarem. O Google disse: “Para dar tempo aos proprietários de sites para se prepararem para esta mudança, esta nova política entrará em vigor a partir de 5 de maio de 2024.”
Inicialmente, esperava-se que isso significasse que o Google desencadearia um algoritmo para punir esses grandes sites. Mas nenhuma atualização de algoritmo jamais atingiu esses sites. Em vez disso, em junho de 2024, o Google explicou que “apenas estaria realizando ações manuais em casos de abuso de conteúdo em larga escala, não algorítmicas.”
Por que apenas manual e não algorítmico? Danny Sullivan, o Google Search Liaison, respondeu a isso em uma entrevista de agosto de 2024:
“Não há ação algorítmica, não espero que haja qualquer ação algorítmica em um futuro próximo… A razão pela qual provavelmente não teremos isso em um futuro próximo é porque não seríamos extremamente cuidadosos e, e pensativos em como o fazemos. Então, isso está apenas demorando e, por enquanto, as ações manuais são o caminho a seguir.”
O Google estava admitindo que usa ações manuais para sites pertencentes a grandes conglomerados de mídia porque os trata de forma diferente dos sites independentes.
Grandes sites podem abusar do Google de forma consciente e intencional – e o pior risco que enfrentam é uma ação manual que vem com a oportunidade de apelar e trabalhar com o Google para que a ação manual seja levantada.
Voltando a Forbes, ela conseguiu se livrar da punição manual. Isso significou que a Forbes teve acesso a um processo de apelação e recuperação – e conseguiu se recuperar da penalidade em apenas alguns meses.
Pouco depois, um representante da Forbes disse ao The Wall Street Journal que “a Forbes continua a fazer parceria próxima com o Google” e que o Google “tem um processo cuidadoso de revisão e apelação para proprietários de sites” que a Forbes pôde usar para que a ação manual fosse levantada rapidamente.
Sites independentes, no entanto, não obtêm tal procedimento de apelação. Nossos sites inteiros podem ser permanentemente “shadowbanned” do Google por um algoritmo. Podem ser apagados por um algoritmo a qualquer momento – arbitrariamente, brutalmente e sem nenhuma oportunidade de apelação.
A única coisa que podíamos fazer era usar nossa voz em nossos blogs e em plataformas como o X.
Denúncias públicas
Em determinado momento, a evidência era simplesmente esmagadora demais para ser ignorada. Muitos sites independentes de qualidade foram atingidos com muita força por muito tempo.
Os algoritmos do Google obviamente não estavam funcionando como o Google dizia que deveriam. O Google até admitiu isso.
Em outubro de 2024, o Google convidou 20 criadores de web independentes, para a sede do Google em Mountain View, Califórnia. O Google nos fez um tour por seu campus (em sua maioria vazio).
E o Google nos deu um pedido de desculpas claro e inequívoco. O Google disse que nossos sites não mereciam nossas “shadowbans”, e que não era nossa culpa.
Mas, como um criador disse no evento, “pedidos de desculpas não pagam as contas.” Todos nós ainda não tínhamos ideia de como poderíamos tirar nossos sites do “shadowban”. Infelizmente, o Google também não tinha uma ideia real.
Sem alternativa
O Google teve a possibilidade de ouvir os criadores no evento.
Em um momento, até mesmo Nate se portou de forma mais agressiva com o executivo do Google, Pandu Nayak, por orientações específicas sobre como os criadores de web deveriam sobreviver no futuro IA-first do Google.
Nayak pareceu visivelmente abalado pelo questionamento, mas no final não deu respostas concretas. Ele fez um comentário informal sobre como poderiam tentar usar IA para criar conteúdo. Mas, além disso, ele apenas divagou sobre como a IA estava mudando a pesquisa.
E, finalmente, essa foi realmente a principal conclusão do evento:
Os Googlers nos disseram claramente que, mesmo que nossas “shadowbans” algorítmicas fossem levantadas, nosso tráfego talvez nunca mais voltasse porque a pesquisa havia sido fundamentalmente alterada pela IA no ano anterior.
O Google quis parecer que o cenário de busca em mudança era resultado de forças da natureza – e não de decisões muito deliberadas do Google. Mas, independentemente disso, a mensagem era clara – a IA está mudando fundamentalmente como o Google funciona, e o antigo ecossistema de busca nunca mais voltará.
O Google prometeu trabalhar na melhoria de seus algoritmos para elevar mais sites independentes como o nosso. Embora eu inicialmente mantivesse alguma esperança, a maioria dos criadores saiu pessimista de que o Google realmente planejava mudar algo.
Infelizmente, o tempo provou que eles estavam certos. Pouco mudou após
O Google lançou os destaques de IA – duas semanas depois de purgar editores independentes
Apenas duas semanas depois que o Google terminou de eliminar os editores independentes, o Google anunciou a próxima fase de seus planos em seu evento anual “I/O”: o Google estava colocando conteúdo de IA diretamente nos resultados de pesquisa com os Destaques de IA.

Os Destaques de IA do Google funcionam extraindo conteúdo de websites, resumindo-o com um LLM e apresentando uma resposta resumida diretamente no Google. Em sua apresentação no I/O, o Google demonstrou um Destaque de IA para uma pergunta sobre um toca-discos quebrado (vídeo aqui, a partir do minuto 51):
Demonstração do Google em 2024 de um Destaque de IA no Google I/O
A demonstração do Destaque de IA do Google no palco mostrou o tecido do contrato social da web se desintegrando em tempo real: O Destaque de IA puxou, resumiu e reformulou ligeiramente o conteúdo do website de origem Audio-Technica.

Notavelmente, o Googler que realizou a demonstração conseguiu “resolver” seu problema sem realmente clicar no website que criou o conteúdo que a ajudou.
Isso apresenta um problema existencial para os editores – se os pesquisadores podem encontrar as informações que criamos sem nunca visitar nossos websites, como devemos obter receita para financiar a criação de conteúdo?
De fato, no ano seguinte, vários estudos independentes descobriram que a presença de Destaques de IA nos resultados de pesquisa reduz as taxas de cliques para editores da web em 15% a 55%. (Fontes: Seer Interactive, Ahrefs, Amisive)
Em vez de clicar nos websites, os Destaques de IA mantêm os pesquisadores clicando no Google – permitindo que o Google gere mais lucro à custa do trabalho árduo dos editores.
O Google planeja usar a IA para monetizar não apenas as perguntas dos pesquisadores, mas também as respostas
Como um proeminente especialista em pesquisa disse, “os Destaques de IA do Google são aparentemente projetados para desviar os cliques dos usuários dos websites e empurrá-los para os anúncios do Google.”
No I/O 2024, o Google anunciou sua visão para um futuro centrado em IA, onde “o Google fará a pesquisa por você.” Apenas uma semana depois, na Google Marketing Live Keynote, revelou planos para “Anúncios que Respondem” – permitindo que o Google monetizasse não apenas as perguntas, mas também as próprias respostas.

O plano do Google está funcionando. A receita de anúncios de pesquisa do Google aumentou 16% no último ano – e isso apesar da concorrência do ChatGPT, da maturidade do mercado de pesquisa e do fato de que a participação de mercado do Google não cresceu.
O Google também favorece suas próprias propriedades nos resultados de pesquisa
O Google eliminou os editores independentes para criar espaço para a IA e anúncios – mas também para que pudesse promover suas próprias propriedades na web.
Lembra como eu disse que as “bolas demolidores algorítmicas” do Google atingiram o setor de viagens com especial dureza? Bem, considere este gráfico da visibilidade de pesquisa do Google Travel nos últimos anos:
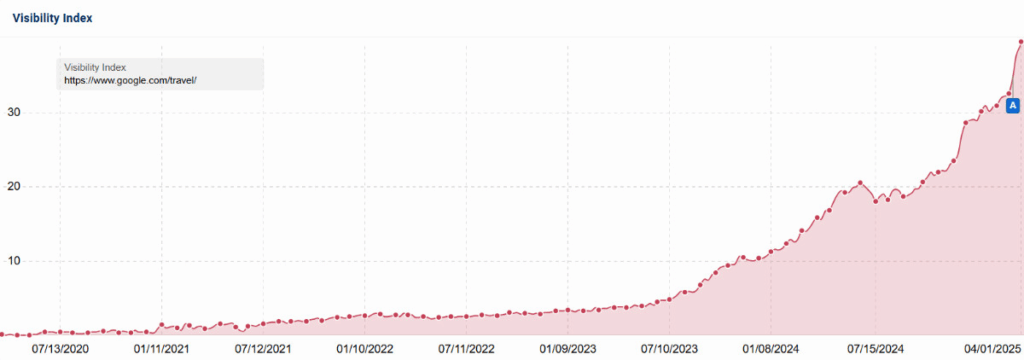
Você pode notar que o gráfico do Google Travel se parece com um inverso quase perfeito do gráfico de referência do site de Nate.
O Google também favorece suas outras propriedades, como YouTube e Google Maps. E o Google injeta agressivamente links de volta para seus próprios resultados de pesquisa dentro dos Destaques de IA, para evitar que os pesquisadores cliquem em websites de terceiros.
Um estudo recente descobriu que “43% dos Destaques de IA apontam de volta para o Google.” O Google consistentemente se favorece acima de todos os outros websites. Embora o Google tenha outro favorito recentemente…
De novo… o Reddit
Além do Google, há um claro vencedor no projeto do Google de reimaginar a busca: o Reddit. As mesmas atualizações de algoritmo que removeram os editores independentes dos resultados de pesquisa também elevaram o Reddit a um grau nunca antes visto na história da busca do Google:
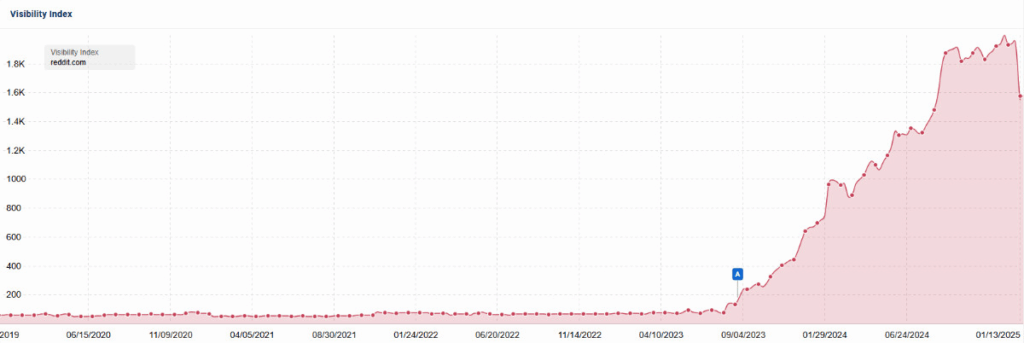
No verão de 2024, Steve Paine, da ferramenta de visibilidade de busca Sistrix, disse ao Business Insider que o crescimento do Reddit foi “sem precedentes.” Ele continuou: “Não houve um website que cresceu tanto em visibilidade de busca tão rapidamente nos EUA em pelo menos nos últimos cinco anos.”
Mas a visibilidade de busca foi apenas parte do que o Google deu ao Reddit. O Reddit também recebeu dinheiro em espécie.
Em 22 de fevereiro de 2024, o Reddit e o Google anunciaram um acordo de licenciamento de IA de US$ 60 milhões por ano. A tática do Reddit em 2023 de ameaçar bloquear os rastreadores do Google aparentemente funcionou.
O acordo, assim como o aumento na visibilidade de busca, chegou em um momento incrivelmente conveniente para o Reddit e seus executivos. Veja bem, quase exatamente um mês após o anúncio do acordo, o Reddit concluiu seu IPO e abriu capital na Bolsa de Valores de Nova York (NYSE).
O Reddit precificou seu IPO em US100 por ação – o que lhe confere um valor de mercado de quase US$ 20 bilhões.
Agora, para ser justo, o Google dirá que as duas coisas – o impulso do Reddit na busca e seu acordo de licenciamento de IA – são completamente alheias e uma total coincidência. Você pode julgar os fatos por si mesmo.
Conspiratório ou coincidência, uma coisa é clara: todo o incidente mostra o quanto o Google tem poder para remodelar toda a Internet a seu bel-prazer em questão de poucos meses. E a IA dará ao Google ainda mais poder para reescrever a Internet.
Mesmo no Brasil, o Reddit teve um desempenho formidável. Cresceu 12x em tráfego estimado nos últimos 2 anos.
O Google planeja usar taxas de licenciamento de IA para controlar quais websites sobreviverão no futuro centrado em IA
Como os websites sobreviverão quando os usuários não precisarem mais clicar? Bem, muitos especialistas em web acreditam que um modelo de taxa de licenciamento de IA é o substituto lógico para o atual contrato social da web de “cliques por conteúdo”.
O Google aparentemente concorda. Sundar Pichai disse recentemente: “Haverá um mercado no futuro, eu acho. Haverá criadores que criarão para modelos de IA e serão pagos por isso. Eu realmente acho que isso faz parte do futuro e as pessoas vão descobrir como.”
Mas Pichai não parece estar com pressa para criar esse mercado ainda. O Google pagou ao Reddit US$ 60 milhões por ano em taxas de licenciamento de IA, mas até agora se recusa a discutir seriamente o licenciamento com a maioria dos outros editores.
Por quê? Bem, o Google explicou sua posição de licenciamento de IA em uma carta recente ao governo do Reino Unido. O Google disse que os editores têm o direito de optar por não ter seu conteúdo aparecendo na pesquisa do Google, mas que “isso não se estende a um direito de ser pago.”
A carta do Google prossegue explicando que o Google está aberto a “negociar acordos e parcerias para uma variedade de situações, incluindo acesso programático a APIs personalizadas, acesso a dados, digitalização, etc.” Mas, o Google disse: “Nenhuma única peça de conteúdo tem valor, e, como tal, a precificação se torna uma questão puramente de barganha.”
Em outras palavras: o Google só está disposto a pagar taxas de licenciamento de IA a partes (como o Reddit) com alavancagem suficiente para negociar contra o monopolista. E, convenientemente para o Google, quanto mais o Google lança a IA, menos alavancagem os editores têm.
Como um reality show, o Google pode lentamente eliminar os editores da web – reduzindo os contrapartes de negociação final do Google a um pequeno punhado de concorrentes que o Google seleciona. E há indicações de que o Google já escolheu quais sites terão a chance de sobreviver em seu futuro impulsionado por IA…
O Google é fortemente tendencioso a favor de poucos grandes conglomerados de mídia
Quando o Google precisou abrir caminho para construir sua pesquisa de IA reimaginada, os editores independentes foram um alvo óbvio para o Google. Afinal, sites pequenos geralmente não têm recursos para processar, como algumas publicações maiores ameaçaram fazer ao longo dos anos (ou, como algumas como a Chegg, realmente fizeram recentemente).
Mas o Google, pelo menos até agora, tratou as megaconglomeradas de mídia de forma diferente – poupando-as de sua “bola demolidora” de IA (pelo menos até agora). Isso, por sua vez, levou a uma incrível consolidação do ecossistema de informações. Na verdade, “quase metade de todo o tráfego do Google vai para apenas um punhado, algumas centenas de sites.” (Fonte: SparkToro)
A maioria desses websites pertence a apenas 16 conglomerados de mídia financiados por capital de risco. Essa consolidação do ecossistema da informação prejudica os usuários de muitas maneiras invisíveis.
Gisele Navarro, do site HouseFresh, documentou extensivamente como algumas grandes marcas de alguns desses conglomerados frequentemente inundam o Google com conteúdo questionável.
Pessoalmente, acho que muitas dessas grandes empresas estão vivendo em tempo emprestado, e que o Google provavelmente virá para suas vagas nos resultados de busca na próxima rodada de seu game show.
Mantenho a esperança de que alguns deles vejam a luz e se juntem aos editores independentes para se manifestar com mais veemência contra o Google. Mas, pelo menos por enquanto, muitos desses grandes conglomerados de mídia parecem contentes em serem permitidos pelo Google a existir dentro do jardim murado do monopolista (por enquanto).
O Google planeja usar a IA para consolidar o fluxo de informações online
O Google já tem o poder de controlar quais fontes de informação os usuários encontram e clicam ao pesquisar. E, como mostrei acima, o Google não tem medo de abusar de seu poder de monopólio para direcionar os usuários a si mesmo, a seus parceiros ou a suas fontes de mídia preferidas.
Mas o que acontece quando o Google controla não apenas as fontes de informação – mas também a própria informação? É exatamente isso que o Google pretende fazer com a IA: tornar-se a fonte singular de todas as informações, opiniões e conselhos na web.
Em breve, talvez não tenhamos que nos preocupar com quais websites recebem cliques da pesquisa – porque o Google não estará enviando cliques para ninguém. A menos, é claro, que você pague ao Google para exibir um “anúncio que responde” às perguntas dos usuários. E aí está o problema…
O Google não está satisfeito com seu monopólio na busca – ele quer um monopólio nas respostas
Como vimos, o executivo do Google, Noam Shazeer, voltou em uma declaração de Larry, mostrando o quão lucrativo é o mercado de “organização da informação”.
De fato, o Google está a caminho de realizar essa oportunidade de quatrilhões de dólares – silenciosamente, e com menos alarde do que a OpenAI. As AI Overviews IA já são usados por 1,5 bilhão de usuários.
É claro, esses 1,5 bilhão não escolheram usar os Destaques de IA – o Google apenas alavancou seu monopólio para forçar os Destaques de IA aos usuários. No evento I/O de 2025 do Google, o CEO do Google, Sundar Pichai, até se gabou de como o Google está alavancando seu monopólio de busca para forçar os Destaques de IA a “mais pessoas do que qualquer produto no mundo.”
No Brasil, ainda há o turbilhão de Discover
Se há uma maneira simples de matar portais de conteúdo útil é tirá-los do Discover. Não chama atenção. Além disso, o próprio Google alertou algumas vezes sobre esse tipo de tráfego ser instável.
Entretanto, isso não era verdade. Para a maior parte dos editores, o tráfego Discover era mais estável que a própria pesquisa, uma vez que sofria menos com grandes eventos e oscilações no interesse de pesquisa.
Em 22 anos trabalhando com SEO, nunca senti tanto editores abalados, diminuindo postos de trabalho e até mesmo fechando negócios.
Vimos acima sobre a qualidade de conteúdo que o Google espera dos sites. Você se lembra?
O que você acha destes conteúdos?

Mesmo para quem gosta da temática, o conteúdo é ruim

Os espaços de vários veículos foram vendidos para empresas que exploram publicidade. Como contrapartida, oferecem ao usuário esse tipo de experiência:
Como tenho tratado sobre esse assunto exaustivamente, deixarei os links para que você possa se aprofundar:
Google Discover: em educação houve quem preferisse falar animais de estimação para ter tráfego
Google Discover: em abril, apenas um grupo seleto se deu bem
Google Discover: Google deixa claro sua preferência por conteúdo inútil, após 40 dias de desordens
Grandes portais de notícias infringem documentações do Google para ter mais tráfego no Discover
Google Discover: quedas não se devem a anúncios de bets ou problemas isolados de UX
Google Discover: profissionais cogitam processar Google por quedas de tráfego
Google Discover: relatório mostra os principais vencedores da atualização e suas características
Google Discover: queda de portais é destaque internacional
Google Discover: Google tem privilegiado determinados sites?
Google Discover: portais de notícias relatam quedas acima de 80%
O que você (sim, você!) pode fazer para salvar a web aberta da tomada de poder da IA do Google
A web aberta está sob ataque do Google e da IA – mas ainda há tempo para salvá-la, desde que todos ajamos juntos rapidamente.
Aqui está o que você pode fazer agora para salvar a web aberta:
- Compartilhe o que o Google está fazendo com a web aberta. Você pode começar compartilhando este artigo. Alternativamente, deixei outros bons artigos para compartilhar na seção de leitura adicional abaixo.
- Converse com editores independentes diretamente. Você não encontrará muitos disso na Internet, mas muitos ainda estamos publicando conteúdo útil escrito por humanos — só precisamos que você nos encontre e nos apoie diretamente.
- Apoie processos existentes. Temos um processo em andamento no Cade, por exemplo, o que você acha de apoiar?
- Se você é um editor independente, compartilhe sua história. Converse com seu público onde quer que ele ainda possa encontrá-lo. Conte a eles o que o Google está fazendo com a web aberta e como eles podem ajudar. Envie para nós!
- Se você é um grande editor, agora é a hora de quebrar o silêncio. Eu sei que muitas grandes publicações têm medo de se manifestar contra o Google. Você pode pensar que conseguirá um acordo de licenciamento de IA. Você pode pensar que o Google o poupará da carnificina da IA. Duvido. Se você trabalha em uma dessas publicações, por favor, pressione seus editores para pararem de ficar em silêncio sobre o que o Google está fazendo com a web aberta com a IA.
Houve uma web antes do Google e haverá uma web depois do Google, desde que todos nós decidamos retomar o controle de nossas vidas online antes que seja tarde demais.
Publisher do "Não é Agência!" e Especialista de SEO, Willian Porto tem mais de 21 anos de experiência em projetos de aquisição orgânica. Especializado em Portais de Notícias, também participou de projetos em e-commerces, como Americanas, Shoptime, Bosch e Trocafone.





